Prompt engineering, like software engineering, has a development life cycle. As we build, measure, and integrate these prompts into an application, they can improve over time and be fine-tuned for increased performance.
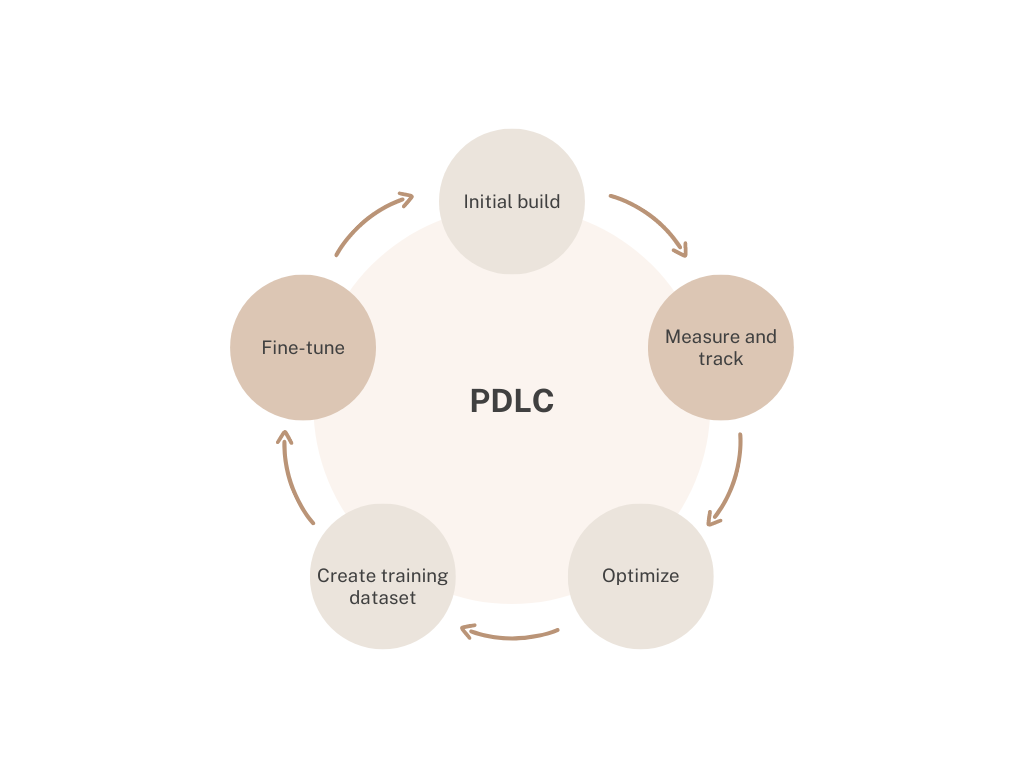
1. Initial Build
In the initial build phase, we build an initial prompt. This prompt does not need to be perfect. It can incorporate techniques such as zero-shot, few-shot, chain-of-thought, choice-shuffle, etc.
The goal of the initial prompt is to build a prompt so that:
- it works 80% of the time
- it can be integrated into the product
- we can start collecting data for review
2. Measure and Track
In the measuring and tracking phase, we aim to collect as much product and prompt usage information as possible. We store generated prompt output and corresponding variables in a database or logging environment. Measuring and tracking output will allow us to optimize and fine-tune future models and ensure they work.
3. Optimize
Optimization aims to review historical prompt data and understand areas of opportunity, edge cases, exceptions, and overall performance. We modify the prompt to increase the accuracy as much as possible.
Optimization will:
- help us save time in the dataset review process
- increase prompt performance
- identify areas where a prompt break-down is required
4. Create Training Dataset
To create a training dataset, we review a large number of samples. Some samples need to be corrected, and others require additional review, input, and feedback before being accepted as part of a training dataset. Creating a training dataset is often time-consuming, but it is a required component of AI-related development work.
The size of the dataset will depend on:
- complexity of output
- LLM models selected to fine-tune
- quality considerations
5. Fine-tune
The last and final step of the prompt development life cycle (PDLC) is to fine-tune an LLM or another type of model based on the training dataset. If a sufficiently large training dataset is created, we can fine-tune or train a smaller model with similar or better performance. Once a model is fine-tuned, we should continue to log, track, and review data to optimize the model further in the future if required.
